KI generierte (Fach-)Arbeiten erkennen
Prolog
Philippe Wampfler vertrat vor einiger Zeit die Auffassung, dass KI-Detektoren funktionieren. Es gibt Fachpersonen wie Doris Wessels, die dem vehement widersprechen. Ein zentraler Ansatz von Philippe ist folgender:
Die funktionierenden Detektoren setzen aber genau so wie die text- oder bildgenerierenden Tools Machine-Learning ein, um KI-gemachte von menschengemachten Produkten zu unterscheiden.
Die minimale Voraussetzung, dass man Modelle speziell mit KI Artefakten trainiert, um diese spezialisierte Anwendung abzudecken, ist eine kostendeckende Nachfrage durch den Markt. Ich glaube, der zugehörige Markt ist – zumindest für die Prüfung von Texten – schlicht zu klein, um ein Modell aufwändig für diesen Anwendungsfall zu trainieren. Als „Techie“ glaube ich eher an eine selbstreflexive Mustersuche der Modelle in den eigenen Vektorräumen mit Systemsprompts wie:
„Welche Anteil des vorliegenden Textes findet du mit hoher Wahrscheinlichkeit in genau der dargebotenen Reihenfolge im Vektorraum deines eigenen Modells?“
Und damit laufen wir in systematischen Probleme der transformerbasierten LLMs, z.B. der prinzipbedingt mangelnden Stabilität: Lässt man den gleichen Text 10x „testen“, erhält man zehn unterschiedliche Prozentwerte für die Wahrscheinlichkeit, dass ein Text KI-generiert ist.
Der Anlass
Ich habe in diesem Jahr 15 Facharbeiten korrigiert. Das ist hier in Niedersachsen die „letzte Runde“, weil man behördlich vor dem „KI-Problem“ bereits insofern kapituliert hat, dass die Facharbeit künftiger Schülergenerationen durch andere Formate ersetzt wird. Lisa Rosa weist dabei nach einmal auf den Zusammenhang zwischen Schreiben und Denken mit Verweis auf Vygotskij hin. Ich halte diese Entscheidung in Bezug auf die Erstellung von Facharbeiten daher für verfrüht.
Ich habe den Schüler:innen gegenüber offen kommuniziert, dass ich KI-Detektoren einsetzen werde und musste mir von Doris Wessels (sie stammt aus einer Nachbargemeinde) allein für die Idee viel Kritik anhören.
Mein Ansatz war folgender:
- Ich nutze für die gesamte Lerngruppe das gleiche Tool (ZeroGPT) und bilde einen Mittelwert der ermittelten Wahrscheinlichkeiten.
- bei hohen Anweichungen nach oben schaue genauer auf bestimmte Textmarker (s.u.) und behalte mir ggf. inhaltliche Nachprüfungen vor.
- Eine unmittelbare Auswirkung auf die Bewertung entsteht durch das Ergebnis eines KI-Detektors allein(!) erstmal nicht.
Erkenntnisse
Die Nutzung eines KI-Detektors ist kompletter Unsinn. Dabei ist es irrelevant, ob er funktioniert oder nicht funktioniert, weil der Text der Facharbeit höchstwahrscheinlich durch inkompetenten Gebrauch von LLMs inhaltlich und strukturell deutlich schlechter wird als durch eigenständige Erarbeitung. Das gilt ausdrücklich nicht für die sprachliche Form.
In diesen Thread auf bildung.social sind einige Textmarker zusammengetragen, die zumindest bei mir gut mit einer hohen Wahrscheinlichkeit im KI-Detektor korrelieren. Sie stammen von mir und der Community (u.a. Tobias Wunder, I. L. Villian)
- Keine direkten Zitate bzw. Auseinandersetzung damit
- Inhaltliche Neuansätze, durch Aneinanderreihung von Quellenzusammenfassungen
- Redundanzen, wenn Quellen zu analogen Schlüssen kommen
- Lehrbuchartiger Sprachduktus, meist „überreduziert“ und dadurch oberflächlich
- Inhaltlich viel zu breite Anlage
- Kaum vorhandene Lesendenführung, fehlende Vernetzung
- Seltsame, unvollständige Aufzählungen ohne Mehrwert
- „Stotterer“ (gleiche Satzteile mehrfach im Satz), z.B. „Es gibt verschiedene Ampelfarben, z.B. rot, gelb, rot, blau.“
- Seltsame, durch Googeln oder Literaturrecherche für SuS kaum auffindbare Belege
- Bei international bedeutsamen Themen eine starke US-Zentrierung der Quellen
- Von Seiten wie books.google.com usw. wird nur der Deeplink Link „zitiert“, obwohl der Text dahinter komplette bibliografische Daten besitzt.
- […]
Jeder dieser Textmarker ist durch Spezifika der LLMs mit Transformeransatz gut erklärbar, die „Stotterer“ etwa durch Modellrauschen oder der Sprachduktus durch zu breites themenübergreifendes Training des Modells.
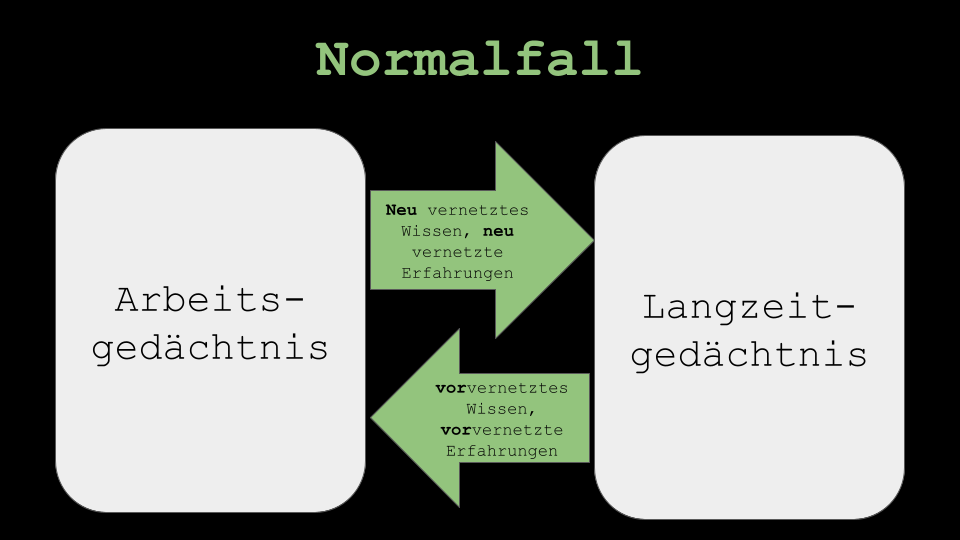
Die häufig zu breite inhaltliche Anlage lässt sich dadurch erklären, dass in Wissensdomänen, in den sich ein Schreiber nicht auskennt, nicht sinnvoll zwischen Relevanz und Irrelevanz unterschieden werden kann und auch die Auswahl eines sinnvollen Fokus erschwert ist. Das passt sehr gut zur Kognitionstheorie mit Langzeit- und Arbeitsgedächtnis.
Daher glaube ich mittlerweile, dass LLMs völlig ungeeignet für Novizinnen in einem Thema sind, wenn sie sich einen Überblick darüber verschaffen wollen oder ohne Vorrecherche Gliederungen mit solchen Werkzeugen erstellen lassen – entgegen häufig beschriebener unterrichtlicher Einsatzszenarien auf Socialmedia.
Ausblick
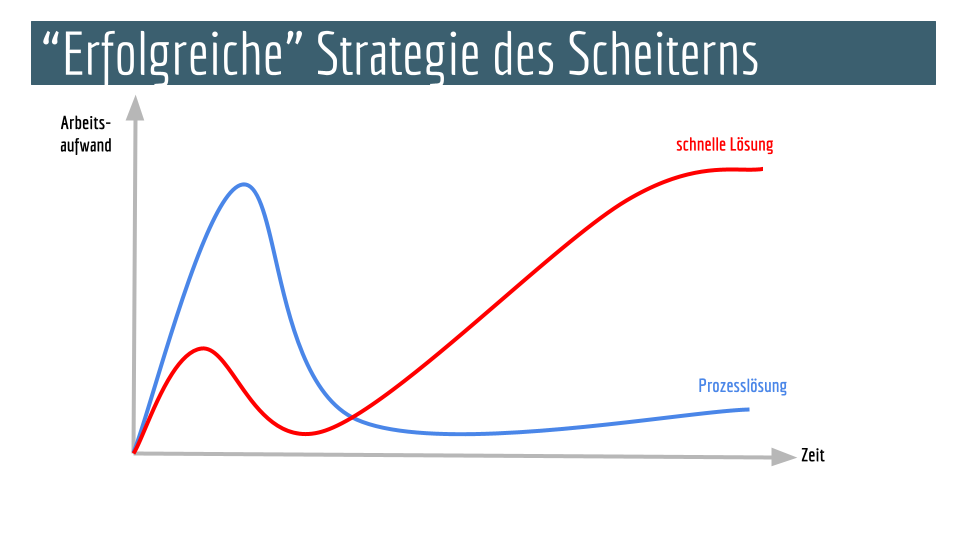
Die häufig angebotene „Lösung“ bei schlechten Ergebnissen durch LLMs besteht darin, den „Fehler“ in mangelnden Prompting-Skills zu sehen. Mich überzeugt das immer weniger, gerade wenn es darum geht, einen geschlossenen Gedankengang unter Verwendung von Sekundärliteratur zu entwickeln. Ein herausragender Text setzt für mich eigene Lebensrealität, eigenen Erfahrungen in der Welt in Bezug zu Erfahrungen aus Literatur, Forschungsergebnissen Dritter usw..
Wir können in Bezug auf LLMs alles daherargumentieren, aber genau an dem fehlenden individuellen Weltbezug muss es systembedingt bei unseren heutigen algorithmischen Ansätzen immer scheitern.
Es gibt Anwendungen, für die LLMs geradezu prädestiniert sind, nämlich bei allem, was im Prinzip entseelt ist und keinen individuellen beruflichen Arbeitsschwerpunkt bildet: Aus PDFs Excelsheets machen, viele Formen von Gutachten, Vermerke Anträge – d.h. Kommunikationssituationen, die im Prinzip kaum durch dialogische, sondern eher parasoziale Diskurse geprägt sind – gerade auch in juristischen Bereichen. Und gerade dort dürfte es hinreichend große Märkte geben, um spezialisierte Nischenmodelle gezielt zu trainieren.